As of March 11, 2025, we’ve released the building blocks of our new Agents platform. For details, see our API docs for our Responses API, Tools including Web Search, File Search, and Computer Use, and our Agents SDK with Tracing. Based on your feedback for the Assistants API beta, we've incorporated key improvements into the Responses API. After we achieve full feature parity, we will announce a deprecation plan of Assistants API later this year, with a target sunset date in the first half of 2026.
What is the Assistants API?
The Assistants API enables developers to easily build powerful AI assistants within their apps. This API removes the need to manage conversation history and adds access to OpenAI-hosted tools like Code Interpreter and File Search. The API also supports improved function calling for 3rd party tools.
Can I still use Assistants API v1 beta?
No. As of December 18, 2024 users no longer have access to the v1 version of the Assistant API beta. We currently only support v2. Please check out this migration guide to convert your API calls from v1 to v2
How do I access it?
The Assistants API is available to anyone with an OpenAI API account, but it is deprecated and will be removed in August 2026. For new projects, use the Responses API instead. If you already use the Assistants API, plan your migration to the Responses API. You can still access existing assistants in the Assistants Playground while the API remains available.
What is an Assistant?
An assistant represents a purpose-built AI that uses OpenAI’s models and can access files, maintain persistent threads, and call tools.
What is a Thread?
A thread is a conversation session between an assistant and a user. Threads simplify application development by storing message history and truncating it when the conversation gets too long for the model’s context length.
What is the File Search tool?
The `file_search` tool implements several retrieval best practices out of the box to help you extract the right data from your files to augment the model’s responses. For more information, please read our developer documentation.
By default, the file_search tool uses the following settings:
Chunk size: 800 tokens
Chunk overlap: 400 tokens
Embedding model: `text-embedding-3-large` at 256 dimensions
Maximum number of chunks added to context: 20
What are the restrictions for File upload?
The restrictions for uploading a File are:
512 MB per file
5M tokens per file
10k files per vector store
1 vector store per assistant
1 vector store per thread
The overall storage limit for each project in an organization is 100 GB.
What are the limitations of the File Search tool?
We have a few known limitations that we're working on adding support for in the coming months:
There is currently no way to modify the chunking, embedding, or retrieval settings.
We don't support parsing of images within documents.
We don't support retrievals over structured file formats (like .csv or .jsonl files). See supported file types.
What are the rate limits for the Assistants API?
The rate limits for the Assistants API are not tied to usage tier and model. Instead, there are default limits by request type, with a couple of exceptions:
GET: 1000 RPM
POST: 300 RPM
DELETE: 300 requests per minute
How is Code Interpreter in the API priced?
Code Interpreter is priced at $0.03 / session. If your assistant calls Code Interpreter simultaneously in two different threads, this would create two Code Interpreter sessions (2 * $0.03). Each session is active by default for one hour, which means that you would only pay this fee once if your user keeps giving instructions to Code Interpreter in the same thread for up to one hour.
How is File Search in the API priced?
File Search is priced at $0.10/GB of vector store storage per day (the first GB of storage is free). The size of the vector store is based on the resulting size of the vector store once your file is parsed, chunked, and embedded.
Any vector stores that were created before April 17th, 2024 will be free until the end of 2024, after which they will either be:
Billed at the current rates (currently $0.10/GB/day) if they have been used at least once in a Run created after April 17th, 2024.
Deleted if they haven’t been used in a single Run between April 17th, 2024 and December 31st, 2024 — this is to avoid you getting billed for vector stores you may have created before this pricing change was announced but never used.
Is there a limit to how many assistants I can create?
There is no limit to how many assistants an org can create.
Is streaming available on the API?
Yes, streaming is available on the Assistants API.
Is JSON mode available in the Assistants API?
Yes, JSON mode is available on the Assistants API via the response_format parameter on the Assistants or Run objects.
Will the Assistants API also manage requests for 3rd party function calls?
No. While function calling enables the model to select tools and format requests for them, executing calls to 3rd party tools is not managed by OpenAI.
How is the data I send to OpenAI handled?
As with the rest of our platform, data and files passed to the OpenAI API are never used to train our models and you can delete your data whenever you require. The data uploaded to the Assistants API is stored indefinitely until a user manually deletes it.
Is DALL-E available via the Assistants API?
At this time, DALL-E is not available.
Is there a UI for the Assistants API?
You can check out the Playground for the Assistants API. Make sure you are in the Assistants view on the left sidebar and using a model compatible with the Tools you wish to toggle on.
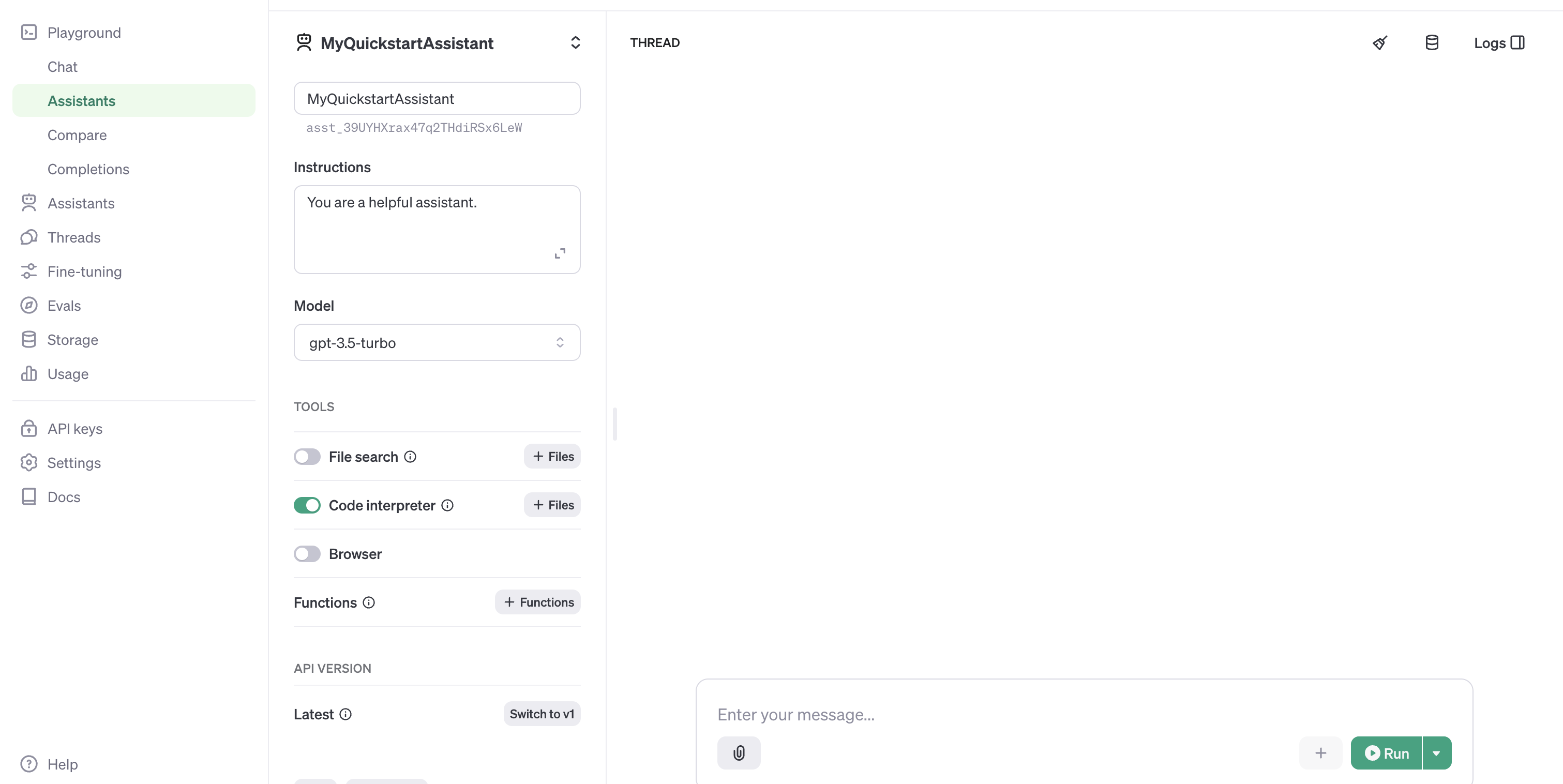
What is the character limit for assistant instructions in the Assistants API?
The assistant instructions field has a maximum length of 256,000 characters.
I’m getting an error such as “The server had an error while processing your request. Sorry about that! You can retry your request, or contact us through our help center at help.openai.com if the error persists. “ What should I do?
If you’re getting this error, it might mean that your prompt is not set up correctly. If you keep retrying the request and it fails, here are some things to try:
make sure to restructure your prompt to treat any function-like commands as functions
add any commands in your prompt as a function to
tools
Why is my File Search tool not working well?
When using the File Search tool, we recommend setting the max_prompt_tokens to no less than 20,000. For longer conversations or multiple interactions with File Search, consider increasing this limit to 50,000, or ideally, removing the max_prompt_tokens limits altogether to get the highest quality results. Read more here.
How can I provide feedback?
We would love to hear your feedback on our Developer Forum, via the Help Center at help.openai.com, or on Twitter @OpenAIDevs.