OpenAI का उद्देश्य ऐसे मॉडल बनाना है जो विभिन्न डोमेन और अनुप्रयोगों में डेवलपर्स के लिए उपयोगी हों. हम शोध प्रगति के माध्यम से और उन्हें वास्तविक दुनिया की चुनौतियों और संदर्भों पर लागू करके अपने मॉडल्स में सुधार करते हैं.
डिफ़ॉल्ट रूप से, हम अपने मॉडल बेहतर बनाने के लिए व्यावसायिक उपयोगकर्ताओं, जिनमें ChatGPT Business, ChatGPT Enterprise, और API शामिल हैं, के लिए अपने उत्पादों से किसी भी input या output का उपयोग नहीं करते हैं. हालांकि, हम मानते हैं कि API उपयोगकर्ताओं को फिलहाल इन मॉडल्स को अपनी विशिष्ट ज़रूरतों के अनुसार विकसित करने में सीमाओं का सामना करना पड़ता है.
इस सुधार में योगदान देने का एक तरीका है OpenAI के साथ फ़ीडबैक, मूल्यांकन और फाइन-ट्यूनिंग डेटा, या API इनपुट और आउटपुट साझा करने के लिए ऑप्ट-इन करना। जो संगठन ऐसा करना चुनते हैं, वे अपने डेटा नियंत्रण सेटिंग्स के माध्यम से इन विकल्पों को प्रोजेक्ट या संगठन स्तर पर प्रबंधित कर सकते हैं। आपके द्वारा साझा किया गया डेटा उपयोग पैटर्न की पहचान करने, मॉडल गुणवत्ता मापने, और मॉडलों के भविष्य के मूल्यांकन और प्रशिक्षण को दिशा देने में मदद के लिए उपयोग किया जाएगा।
OpenAI API का उपयोग करते समय आपके डेटा और गोपनीयता पर नियंत्रण हमेशा आपके पास रहता है। आप किसी भी समय अपनी सेटिंग्स बदल सकते हैं और फिर से ऑप्ट-आउट करने का विकल्प चुन सकते हैं। लोगों की गोपनीयता की रक्षा में मदद के लिए, हम किसी भी मॉडल सुधार और प्रशिक्षण के लिए उपयोग से पहले अपने प्रशिक्षण डेटासेट में व्यक्तिगत जानकारी की मात्रा कम करने के कदम उठाते हैं।
कृपया ध्यान रखें कि अपने संगठन से OpenAI को डेटा साझा करके, आप पुष्टि करते हैं कि इस लेख में वर्णित अनुसार OpenAI द्वारा इस डेटा को संसाधित और उपयोग करने के लिए आपके पास उचित अनुमतियाँ हैं। कृपया अपने द्वारा साझा किए जाने वाले डेटा में कोई संवेदनशील, गोपनीय, या स्वामित्व संबंधी जानकारी शामिल न करें।
OpenAI के साथ डेटा साझा करने के लिए ऑप्ट-इन करने हेतु आपको संगठन का स्वामी होना होगा। जिन खातों में ज़ीरो डेटा रिटेंशन सक्षम है, वे हमारे डेटा साझाकरण तंत्र में ऑप्ट-इन नहीं कर सकते।
API डैशबोर्ड के माध्यम से फ़ीडबैक कैसे साझा करें
Playground के माध्यम से फ़ीडबैक साझा करने की क्षमता सभी संगठनों के लिए डिफ़ॉल्ट रूप से अक्षम होती है। यदि कोई खाता स्वामी अपने संगठन के लिए API मॉडल फ़ीडबैक साझा करने के लिए ऑप्ट-इन करना चाहता है, तो वह संगठन सेटिंग्स पेज पर “enabled” या “enabled for selected projects” चुन सकता है।

जब इसे “enabled” पर सेट किया जाता है, तो संगठन के सदस्यों को Playground में मॉडल प्रतिक्रियाओं पर “thumbs down” बटन दिखाई देगा। इस पर क्लिक करने पर, उपयोगकर्ता को हमारे फ़ीडबैक सिस्टम के साथ उस बिंदु तक की बातचीत (इनपुट, आउटपुट और अपलोड की गई फ़ाइलों सहित) साझा करने का विकल्प मिलेगा।
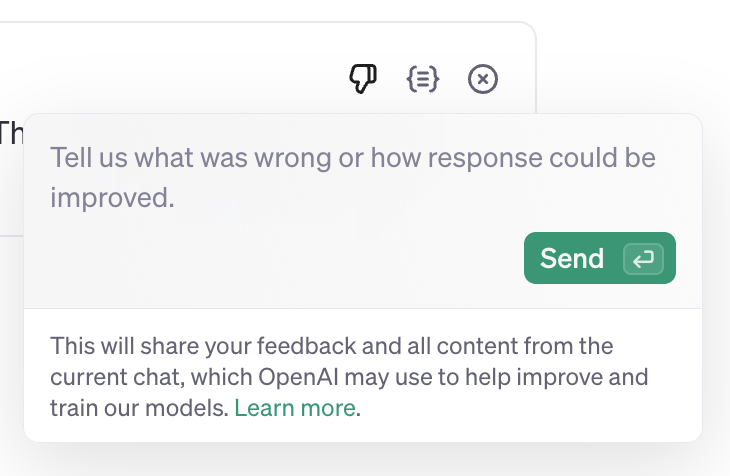
OpenAI के साथ मूल्यांकन और फाइन-ट्यूनिंग डेटा कैसे साझा करें
डिफ़ॉल्ट रूप से, सभी संगठनों के लिए मूल्यांकन और फाइन-ट्यूनिंग डेटा का डेटा साझाकरण अक्षम होता है। खाता स्वामी अपनी संगठन की सेटिंग्स पेज के माध्यम से, या तो सभी प्रोजेक्ट्स के लिए या केवल चुने हुए प्रोजेक्ट्स के लिए, इस सुविधा में ऑप्ट-इन कर सकते हैं। खाता स्वामी किसी भी समय इन सेटिंग्स को बदल सकते हैं और फिर से ऑप्ट-आउट करना चुन सकते हैं। यह सेटिंग कुछ संगठनों के लिए उपलब्ध नहीं है, जिनमें वे ग्राहक शामिल हैं जिनके लिए ज़ीरो डेटा रिटेंशन सक्षम है।
जब इसे 'Enabled' पर सेट किया जाता है, तो सक्षम प्रोजेक्ट्स पर OpenAI को भेजे गए मूल्यांकन और फाइन-ट्यूनिंग डेटा OpenAI के साथ साझा किए जाएंगे। आपके द्वारा OpenAI के साथ साझा किए गए मूल्यांकन वर्तमान में प्रति सप्ताह 7 रन तक बिना किसी लागत के संसाधित किए जाते हैं। रिइन्फोर्समेंट फाइन-ट्यूनिंग जॉब्स के लिए डेटा साझा करते समय, परिणामस्वरूप मॉडलों का बिल रियायती इन्फ़रेंस दरों पर किया जाएगा।

OpenAI के साथ इनपुट और आउटपुट कैसे साझा करें
डिफ़ॉल्ट रूप से, सभी संगठनों के लिए डेटा साझाकरण इनपुट और आउटपुट अक्षम होता है। खाता स्वामी अपनी संगठन की सेटिंग्स पेज के माध्यम से, या तो सभी प्रोजेक्ट्स के लिए या केवल चुने हुए प्रोजेक्ट्स के लिए, इस सुविधा में ऑप्ट-इन कर सकते हैं। खाता स्वामी किसी भी समय इन सेटिंग्स को बदल सकते हैं और फिर से ऑप्ट-आउट करना चुन सकते हैं। यह सेटिंग कुछ संगठनों के लिए उपलब्ध नहीं है, जिनमें Enterprise और वे ग्राहक शामिल हैं जिनके लिए ज़ीरो डेटा रिटेंशन सक्षम है।

जब इसे 'Enabled' पर सेट किया जाता है, तो सक्षम प्रोजेक्ट्स पर OpenAI को भेजे गए इनपुट और आउटपुट OpenAI के साथ साझा किए जाएंगे।
OpenAI के साथ साझा किए गए prompts और completions पर मानार्थ टोकन
कुछ संगठन OpenAI के साथ साझा किए गए ट्रैफ़िक पर दैनिक मानार्थ टोकन के लिए पात्र हो सकते हैं.
मुझे कैसे पता चलेगा कि मैं मुफ़्त टोकन के लिए पात्र हूँ या उनके लिए नामांकित हूँ?
आप अपने डेटा शेयरिंग सेटिंग्स पेज पर जाकर और यह पुष्टि करके देख सकते हैं कि आप ऑफ़र के लिए पात्र हैं या नहीं कि आपको “OpenAI के साथ साझा किए गए ट्रैफ़िक पर मुफ़्त दैनिक उपयोग के लिए आप पात्र हैं” ऑफ़र दिखाई देता है या नहीं. जब आप डेटा शेयरिंग सक्षम करते हैं और निःशुल्क टोकन के लिए योग्य होते हैं, तो आपको “आप निःशुल्क दैनिक टोकन के लिए नामांकित हैं” दिखाई देगा.
इस प्रोग्राम को समाप्त करने से पहले OpenAI 30 दिन पहले सूचना देगा.
यह Tiers 3-5 में पात्र उपयोगकर्ताओं के लिए ऑफ़र का रूप है:

इसी तरह, Tiers 1-2 में पात्र उपयोगकर्ताओं के लिए ऑफ़र ऐसा दिखता है:

अगर आपको अपने डेटा शेयरिंग पेज पर यह भाषा नहीं दिखती है, तो आप इस समय मानार्थ टोकन के लिए पात्र नहीं हैं.
मैं कैसे पुष्टि कर सकता हूँ कि मुझे मुफ़्त दैनिक टोकन मिल रहे हैं, क्या वे अपने-आप लागू होते हैं या मुझे ऑप्ट-इन करना होगा?
अगर आप OpenAI के साथ ट्रैफ़िक साझा करने के लिए ऑप्ट-इन करते हैं और निःशुल्क टोकन ऑफ़र के लिए योग्य हैं, तो निःशुल्क टोकन नीचे सूचीबद्ध मॉडल पर OpenAI के साथ साझा किए गए ट्रैफ़िक पर अपने-आप लागू होंगे.
Fine-tuned models, fine-tuning training, evals, और tool use शामिल नहीं हैं.
ध्यान दें कि आपको केवल उस ट्रैफ़िक पर ही मानार्थ टोकन मिलेंगे जो OpenAI के साथ साझा किया गया है, इसलिए यदि आप केवल चुने हुए प्रोजेक्ट्स पर ट्रैफ़िक साझा करने के लिए ऑप्ट-इन करते हैं, तो केवल उन्हीं प्रोजेक्ट्स का उपयोग मुफ्त टोकन के लिए योग्य होगा। OpenAI मॉडल और मुफ्त टोकन इस्तेमाल करने के लिए आपके खाते में सकारात्मक शेषराशि होना ज़रूरी है.
आप अपने उपयोग डैशबोर्ड पर उपयोग गतिविधि (जहां मुफ्त टोकन आपके कुल में शामिल होंगे) की तुलना लागत से (जहां मुफ्त टोकन लागत के रूप में नहीं दिखेंगे) करके अपने मुफ्त टोकन उपयोग की पुष्टि कर सकते हैं। उपयोग डैशबोर्ड पर अपना पूरा उपयोग देखने के लिए “इनपुट टोकन” और “आउटपुट टोकन” दोनों चुनना सुनिश्चित करें।
आप अपने https://platform.openai.com/usage/chat-completions डैशबोर्ड पर भी मानार्थ टोकन देख सकते हैं और “service tier” के अनुसार समूहित कर सकते हैं। मुफ्त टोकन “data sharing incentive tier - input/output tokens” के रूप में दिखाए जाएंगे। कुल उपयोग देखने के लिए इनपुट और आउटपुट टोकन दोनों शामिल करना सुनिश्चित करें। कृपया ध्यान दें कि डेटा शेयरिंग इंसेंटिव टियर टोकन की कुल संख्या अनुरोध के आकार के आधार पर ठीक 1M या 10M नहीं भी हो सकती है (नीचे “टोकन कोटा सीमा कैसे काम करती है और यह कब रीफ़्रेश होती है?” देखें)।
इस ऑफ़र में कौन-से मॉडल शामिल हैं?
यह ऑफ़र केवल नीचे दिए गए मॉडल पर उपलब्ध है, और टोकन कोटा मॉडल समूहों में साझा होता है. फाइन-ट्यून किए गए मॉडल, फाइन-ट्यूनिंग प्रशिक्षण, मूल्यांकन और टूल उपयोग शामिल नहीं हैं.
1M टोकन समूह (उपयोग टियर 1-2 के लिए 250K):
gpt-5.6-sol
gpt-5.5-2026-04-23
gpt-5.4-2026-03-05
gpt-5.2-2025-12-11
gpt-5.1-2025-11-13
gpt-5.1-codex
gpt-5-codex
gpt-5-2025-08-07
gpt-5-chat-latest
gpt-4.5-preview-2025-02-27 (7/14/25 से डिप्रिकेटेड और बंद)
gpt-4.1-2025-04-14
gpt-4o-2024-05-13
gpt-4o-2024-08-06
gpt-4o-2024-11-20
o3-2025-04-16
o1-preview-2024-09-12
o1-2024-12-17
10M टोकन समूह (उपयोग टियर 1-2 के लिए 2.5M):
gpt-5.6-terra
gpt-5.6-luna
gpt-5.4-mini-2026-03-17
gpt-5.4-nano-2026-03-17
gpt-5.1-codex-mini
gpt-5-mini-2025-08-07
gpt-5-nano-2025-08-07
gpt-4.1-mini-2025-04-14
gpt-4.1-nano-2025-04-14
gpt-4o-mini-2024-07-18
o4-mini-2025-04-16
o1-mini-2024-09-12
codex-mini-latest
टोकन कोटा सीमा कैसे काम करती है और यह कब रीफ़्रेश होती है?
आपको gpt-5, gpt-5-codex, gpt-5-chat-latest, gpt-4.5-preview (7/14/25 से अप्रचलित और बंद), gpt-4.1, gpt-4o, o1, o3 और o1-preview मॉडल में प्रति दिन 1M (टियर 1-2 के लिए 250k) तक टोकन साझा मिलते हैं, और gpt-5-mini, gpt-5-nano, gpt-4.1-mini, gpt-4.1-nano, gpt-4o-mini, o1-mini, o4-mini और codex-mini-latest मॉडल में प्रति दिन 10M (टियर 1-2 के लिए 2.5M) तक टोकन साझा मिलते हैं.
अगर आप इन मॉडल समूहों में 1M/250k या 10M/2.5M की संयुक्त सीमा से अधिक उपयोग करते हैं, तो अतिरिक्त उपयोग का बिल सामान्य दरों पर लिया जाएगा. उदाहरण के लिए, अगर आप एक दिन में o1 पर 750k टोकन और फिर gpt-4o पर 500k टोकन उपयोग करते हैं, तो अतिरिक्त उपयोग के रूप में 250k टोकन का बिल लिया जाएगा.
हर नए अनुरोध के लिए, हम उस दिन के आपके चल रहे कुल के मुकाबले जांच करते हैं. यदि कोई एक अनुरोध आपके दैनिक कुल को टोकन कोटा से ऊपर ले जाता है, तो उस पूरे अनुरोध का बिल सामान्य दरों पर लगाया जाता है.
उदाहरण के लिए, 1M टोकन दैनिक कोटा के लिए:
| समय (UTC) | अनुरोध में टोकन | चल रहा कुल | मुफ़्त या बिल किया गया? |
| 09:15 | 120 k | 120 k | मुफ़्त |
| 12:40 | 140 k | 260 k | मुफ़्त |
| 14:30 | 150 k | 410 k | मुफ़्त |
| 16:00 | 150 k | 560 k | मुफ़्त |
| 18:05 | 150 k | 710 k | मुफ़्त |
| 20:20 | 150 k | 860 k | मुफ़्त |
| 22:15 | 115 k | 975 k | मुफ़्त |
| 23:10 | 30 k | 1 005 k | बिल किया गया (पूरा 30k) |
इस उदाहरण में, पहले सात अनुरोध मुफ़्त हैं. आठवां अनुरोध कुल को 1 million टोकन से आगे ले जाएगा, इसलिए उसका पूरा शुल्क लिया जाता है. मुफ़्त-टोकन काउंटर हर दिन 00:00 UTC पर रीसेट हो जाता है.
6 मार्च, 2025 से, टोकन हर दिन 00:00 UTC समय पर रीफ़्रेश होते हैं. बेहतर predictability और observability की अनुमति देने के लिए हमने यह बदलाव किया.
अगर मैं अपना डेटा साझा नहीं करना चाहता या ये टोकन प्राप्त नहीं करना चाहता, तो क्या मैं ऑप्ट आउट कर सकता हूँ?
आप अपने डेटा शेयरिंग सेटिंग्स पेज पर किसी भी समय ऑप्ट आउट कर सकते हैं.
मेरे API संगठन में इस सेटिंग को चालू / बंद करने की पहुँच किसे है?
सिर्फ़ संगठन के मालिकों के पास ही इस सेटिंग तक पहुँच और इसे चालू / बंद करने की क्षमता होती है.
आपका डेटा कैसे संभाला जाता है, इसके बारे में आप इस हेल्प सेंटर लेख और हमारे एंटरप्राइज़ गोपनीयता पेज पर अधिक पढ़ सकते हैं.